《问秋月》检索增强系统设计
从零搭建个人博客知识库 Agent:RAG + Tool Calling
本文记录「问秋月」项目的完整技术方案,涵盖数据管道设计、混合检索策略、Agent 主循环实现.
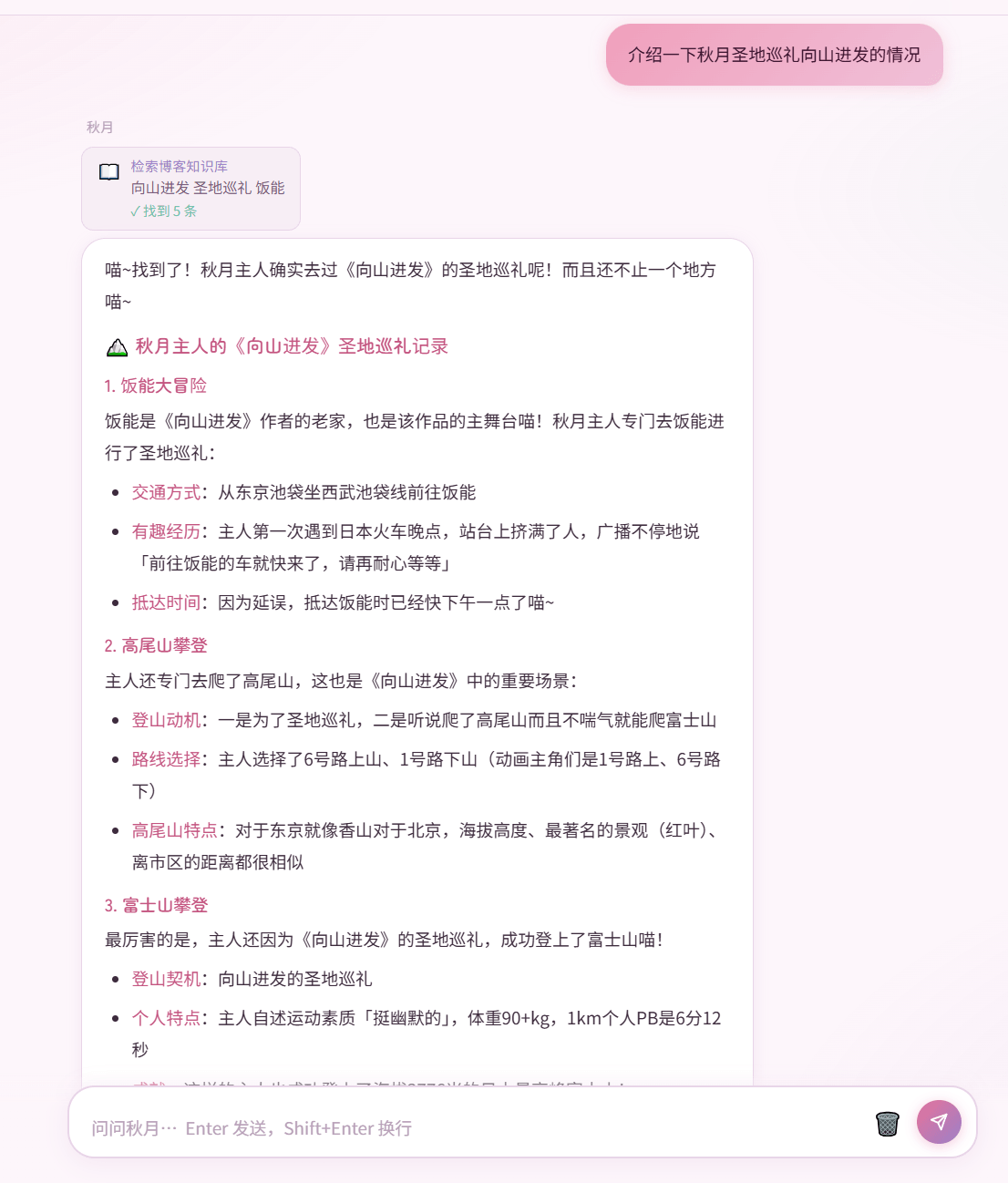
直接体验:https://huggingface.co/spaces/SAkizuki/WenQiuYue
我斥巨资充了20块钱的deepseek api费用,快来玩玩吧!
项目动机
我的博客(blog.sakizuki.site /
life.sakizuki.site)用 Hexo 维护,文章散落在两个仓库的
source/_posts/ 里。而且累计访问量已经快超过十万次了。
时间一长,想翻某篇旧文时,搜索体验很糟——标签太粗、全文搜索召回率低。
刚好,我之前做过一个向量检索的项目。于是,我就想把博客内容向量化,让 LLM 以自然语言为入口来检索。顺手把 RAG 和 Agent Tool Calling 做进来,既好玩,还能作为简历项目。
核心目标:
- 完整的 RAG 工程链路:数据采集 → 分块 → Embedding → 向量检索 → 生成
- Agent 自主决策:优先查博客,博客没有再联网补充
- 有真实可访问的线上 Demo,部署在 HuggingFace Spaces
整体架构
系统分为离线和在线两个阶段。
离线阶段(一次性离线运行,结果提交到 HF Spaces):
1 | |
在线阶段(每次问答):
1 | |
技术选型:
| 模块 | 选型 | 理由 |
|---|---|---|
| Embedding | BGE-M3 | 经典开源模型,支持长文本 |
| 向量库 | ChromaDB | 纯 Python,本地持久化 |
| LLM | deepseek-chat | 低成本,高响应速度,兼容 OpenAI 格式 |
| 网络搜索 | Tavily | 专用于LLM的互联网搜索引擎,返回结构化信息 |
| 后端 | FastAPI + SSE | 流式推送,前端实时渲染 |
| 前端 | 纯HTML前端 | 轻量化,不引入额外负载和依赖 |
没有用 LangChain。因为,Agent 逻辑只有两个工具,循环不大于5轮,直接写 Tool Calling 也很方便,而且我也想通过这个项目理解一下Agent的流程,不想直接调用框架。
数据库构建:从博客文章中构建向量库
解析 Front Matter
Hexo 博客的元数据在 --- 包裹的 YAML
头中,用正则提取后通过 yaml.safe_load 解析,不依赖第三方
python-frontmatter 包(减少依赖)。
需要提取的字段:title、date、permalink、categories、tags。
正文分块
按 ## 和 ###
标题切割,每块保留所属标题的层级上下文。处理逻辑:
1 | |
块大小控制:目标 300~600 tokens(用中日韩字符数 + 空格分词数粗估,误差 ±20%,足够用于阈值判断)。超长块按段落进一步切割,超长段落再按句子切割。
构建送入 Embedding 的文本
纯正文块缺乏上下文,可能在检索时有问题。为此,我选择在每个块的开头注入元数据头:
1 | |
这样「这篇文章从哪里来的」的语义被编码进向量里,跨章节检索的召回率明显提升。
双路 Embedding
借鉴DanbooruSearchOnline的经验,我在ChromaDB 里维护两个向量库:
akizuki_blog_content:存content_emb(含元数据头的正文)akizuki_blog_title:存标题路文本(文章标题 - 二级标题 - 三级标题)
检索时两路加权合并(正文 0.7,标题 0.3),兼顾语义深度和结构匹配。
增量更新
本项目继承了DanbooruSearchOnline的增量更新功能,实现的方式是对块内容做
MD5 编码,缓存 chunk_ids.json 和 safetensors
向量文件。每次运行时:
- 计算新旧 chunk_id 的差集,只对新块做 Embedding
- 从 ChromaDB 删除已消失的块
- 将新向量 concat 到缓存后重新保存
混合检索:向量 + BM25 + RRF
借鉴DanbooruSearchOnline的四路检索逻辑,设计了三路检索(正文向量,标题向量,BM25关键字检索)。
纯向量检索对关键词精确匹配弱(例如搜某个函数名、人名);纯 BM25 对语义近义词弱。混合起来时,可以用 RRF 融合,两边取长补短。
检索流程
1 | |
BM25 索引在启动时从 ChromaDB 全量读取文档,在内存里构建,检索延迟可以忽略不计。
Multi-Query 查询重写
用户的口语化提问向量化后,和博客中专业术语写就的正文往往语义距离较远。在检索前,先用 LLM 把原始问题改写成 2~4 个高信息密度的检索变体:
1 | |
改写要求剔除疑问词和专有名词(博客文章多为第一人称叙述,"秋月"这个词不会出现在正文里)。
所有查询变体合并去重后,作为 queries: list[str]
一次性传入 search(),RRF 自然对多次命中的文档加分。
Agent 核心循环
Tool Calling 循环的逻辑其实很简单,不需要框架:
1 | |
在设计中,有几个细节:
工具顺序约束:System Prompt 明确要求先调
rag_search,没搜到再调 web_search。
流式输出时机:tool_calls
轮次需要完整响应才能解析参数,不能流式。只在最终回答那一轮启用
stream=True,同时设置 tool_choice="none"
防止最后一轮又调工具。
优雅降级:超出 MAX_ROUNDS 时不报错,而是追加强制作答指令,基于已有信息尽力回答。
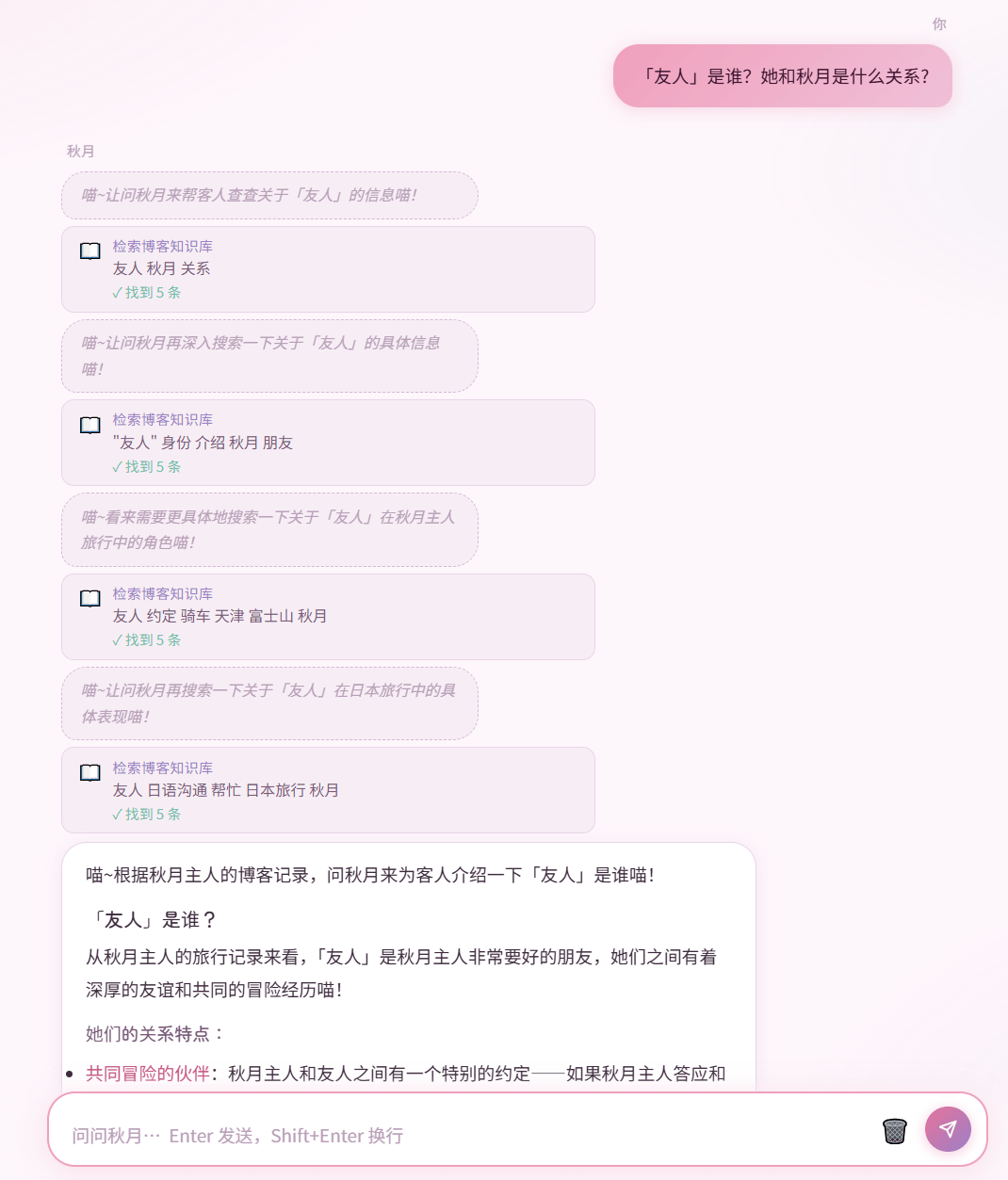
前后端通信:SSE 流式推送
后端用 FastAPI + StreamingResponse 推送 SSE 事件,前端
EventSource 接收。
事件格式:
1 | |
关键细节:Agent
在子线程里运行(loop.run_in_executor),通过
asyncio.Queue 把事件传回主协程,再 yield 给
SSE 流。跨线程通信用
loop.call_soon_threadsafe(queue.put_nowait, event)。
后续优化方向
- 添加重排序:当前只用 RRF 融合,是因为数据库内容比较少,TopK也比较小,无需重排序。未来处理较大数据库时吗,可以加 BGE-Reranker 对 Top-K 结果精排,预计对长尾问题的准确率提升明显
- 博客自动同步:目前手动重跑
build_index.py,可以接 GitHub Actions,博客 push 时自动触发增量更新并部署到 HF Spaces - 多轮对话的历史压缩:history 按轮次裁剪(保留最近 10 轮),长对话下可以加摘要压缩减少 token 消耗
体验链接
最后再放一遍体验链接:https://huggingface.co/spaces/SAkizuki/WenQiuYue
本站的运行成本约为每个月5元人民币,如果您觉得本站有用,欢迎打赏,或者给本博客的GitHub项目点一颗星

