信息论笔记
信息的统计度量
信息量
自信息量
从信源中获取信息的过程就是其不确定性缩减的过程,在统计分析中,使用概率作为衡量不确定性的一种度量。因此,信息量和概率是紧密相关的。任意事件的自信息量的定义为该事件发生的概率的对数的负值,即:
在总体\(X\)中,事件\(x_i\)发生的信息量为: \[ I(x_i)=-\log p(x_i) \] 可见:小概率事件包含的不确定性大,所以它带来的信息量也大。
信息量所用的单位随着对数的底变化而变化,常用的有:
| 底数 | 单位 |
|---|---|
| 2 | 比特(bit) |
| e | 奈特(nat) |
| 10 | 哈特(hat) |
需要说明的是,信息量本身是纯数,没有量纲。这里的“单位”只是为了表示不同底的对数值。
二维联合总体\(XY\)上的元素的信息量为: \[ I(x_iy_i)=-\log p(x_iy_i) \] 在二维联合总体中,事件\(x_i\)在事件\(y_i\)给定的条件下的条件自信息量为: \[ I(x_i\mid y_j)=-\log p(x_i\mid y_j)=-\log \frac {p(x_iy_j)}{p(y_j)} \]
互信息量
对于一个信息传输系统来说,如果信道中没有干扰,那么信源发出信号\(x_i\)以后,信宿一定可以准确地收到消息,此时获得的信息量就是\(x_i\)的不确定度\(I(x_i)\),即信源发出的\(x_i\)所含有的全部信息。但是实际上信道不可能没有干扰,这时候\(x_i\)通过信道会产生污染,信宿收到的消息\(y_i\)将不同于\(x_i\),只能通过条件概率\(p(x_i\mid y_i)\)推测信源发出\(x_i\)的概率。
对于两个离散随机总体\(XY\),事件\(y_j\)的出现给出关于事件\(x_i\)的信息量定义为互信息量,为: \[ I(x_i;y_j)=\log\frac{P(x_i\mid y_j)}{p(x_i)}=I(x_i)-I(x_i\mid y_j) \] 意思是,互信息量是一种不确定性的度量,等于先验的不确定性减去尚存在的不确定性。
互信息量有以下性质:
互易性: \[ I(x_i;y_j)=I(y_j;x_i) \]
可以为0:当\(x_i,y_j\)相互独立时,互信息量为零
可正可负:正值意味着事件\(y_j\)的出现有助于肯定事件\(x_i\)的出现,反之则是不利。
任何两个事件之间的互信息量不大于其中任意一个事件的自信息量
在联合总体\(XYZ\)中,给定\(z_k\)的条件下,\(x_i\)和\(y_j\)的互信息量叫做条件互信息量,即: \[ I(x_i;y_j\mid z_k)=\log \frac{p(x_i\mid y_jz_k)}{p(x_i\mid z_k)} \] 在上述联合总体上,还有\(x_i\)和\(y_jz_k\)之间的互信息量,有: \[ I(x_i;y_jz_k)=I(x_i;y_j)+I(x_i;z_k\mid y_j) \] 意思是:\(y_jz_k\)同时出现提供的有关\(x_i\)的信息量等于\(y_j\)提供的信息量和给定\(y_j\)的条件下,\(z_k\)提供的信息量之和。
离散集(总体)的平均自信息量
之前讨论的自信息量都是对于一个事件\(x_i\)来说的。为了讨论整个\(X\)总体,需要定义平均自信息量: \[ H(X)=E[I(x_i)]=-\sum_{i=1}^n p(x_i)\log p(x_i) \] 平均自信息量也叫做总体\(X\)的信息熵。因为信息熵仅仅是总体的概率分布的函数,所以又可以记作: \[ H(X)=H(\mathbf P)=H(p_1,p_2,\cdots,p_n)=-\sum_{i=1}^n p_i\log p_i \] 其中\(\sum_{i=1}^np_i=1\),所以它实际上是一个\(n-1\)元函数。
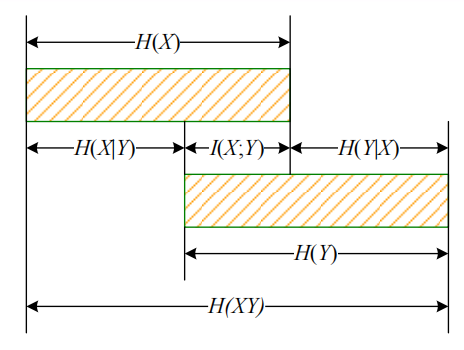
在联合集\(XY\)上,条件自信息量\(I(y\mid x)\)的概率的加权平均值定义为条件熵,即: \[ H(Y\mid X)=\sum_{xy}p(x_i,y_j)I(y_j\mid x_i) \] 对于条件熵,有: \[ \begin{aligned} & H(Y \mid X) \leq H(Y) \\ & H(X \mid Y) \leq H(X) \end{aligned} \] 在联合集\(XY\)上,每对元素的自信息量的概率加权平均值定义为联合熵,即: \[ H(X,Y)=\sum_{xy}p(x_iy_j)I(x_i,y_j) \] 对于联合熵,有: \[ H(X,Y)\leq H(X)+H(Y) \] 当X和Y统计独立时,取得等号。
熵函数有以下特征:
对称性:指无论如何改变概率矢量\(\mathbf P\)中的元素排列顺序,\(H(\mathbf P)\)保持不变
非负性:\(H(X)\geq 0\),当且仅当\(\mathbf P\)中有且只有一个\(1\),其它全是\(0\)
扩展性: \[ \lim _{\epsilon \to 0}H_{n+1}(p_1,\cdots,p_n,\epsilon)=H_{n}(p_1,\cdots,p_n) \] 意思是:一个事件的概率同总体中其它事件相比极小时,它对于总体熵的贡献可以忽略不计。
可加性: \[ H(X,Y)=H(X)+H(Y\mid X)=H(Y)+H(X\mid Y) \]
极值性 \[ H(\mathbf P)\leq H(\frac 1n,\cdots,\frac 1n)=\log n \]
上凸性:\(H(\mathbf P)\)是\(\mathbf P\)的严格上凸函数,即:
对于两个概率矢量\(\mathbf{P,P'}\),有: \[ \forall \alpha \in (0,1),H[\alpha \mathbf P+(1-\alpha)\mathbf P']>\alpha H(\mathbf P)+(1-\alpha)H(\mathbf P') \]
离散集的平均互信息量
在联合集\(XY\)上,由\(y_j\)提供的关于集\(X\)的平均条件互信息量是由\(y_j\)提供的关于元素\(x_i\)的互信息量\(I(x_i;y_j)\)的加权平均,即: \[ I(X;y_j)=\sum_{x_i\in X}p(x_i\mid y_j)I(x_i;y_j) \] 平均条件互信息量在\(Y\)上的加权平均是两个总体的平均互信息量,即: \[ I(X;Y)=\sum_{y_j\in Y}p(y_j)I(X;y_j) \] 平均互信息量非负、互易,而且和通信熵具有如下的关系:
离散信源
离散无记忆信源
离散无记忆信源可以用下面的概率分布描述: \[ \left[\begin{array}{l} X \\ P \end{array}\right]=\left[\begin{array}{cccc} \alpha_1 & \alpha_2 & \cdots & \alpha_q \\ p\left(x_1\right) & p\left(x_2\right) & \cdots & p\left(x_q\right) \end{array}\right] \] 其\(N\)次扩展信源\(X^N\)是具有\(q^N\)个符号的离散无记忆信源,为: \[ \left[\begin{array}{c} X^N \\ p \end{array}\right]=\left[\begin{array}{cccc} \alpha_1 & \alpha_2 & \cdots & \alpha_{q^N} \\ p\left(\alpha_1\right) & p\left(\alpha_2\right) & \cdots & p\left(\alpha_{q^N}\right) \end{array}\right] \] \(N\)次扩展信源的熵为原信源的\(N\)倍,即: \[ H(X^N)=NH(X) \]
离散平稳信源
如果一个信源产生的随机序列\(X_i,i=1,2,\cdots\)满足:
所有\(x_i\)都取值于有限的信源符号集合\(A=\{a_1,a_2\cdots,a_q\}\)
对所有的非负整数\(N,i_1,i_2,\cdots,i_N,h\),对所有的\(x_1,x_2,\cdots\in A\),有: \[ P(X_{i_1}=x_1,\dots,X_{i_N}=x_n)=P(X_{i_1+h}=x_1,\cdots,X_{i_N+h}=x_n) \]
也就是说,这个信源发出的符号序列的概率分布和时间起点无关,那么这个信源称为离散平稳信源。
如果有 \[ P(X_i=x)=P(X_j=x) \] 即任意时刻信源发出单个符号的概率相同,那么叫做“一维平稳信源”;如果随机序列的二维联合分布也和时间起点无关,称为二维平稳信源。如果对任意正整数\(N\),其联合分布都和时间起点无关,称为完全平稳信源,简称为平稳信源。
对二维平稳信源来说,有联合熵: \[ H(\mathbf{X})=H\left(X_1 X_2\right)=-\sum_{i=1}^q \sum_{j=1}^q p\left(a_i a_j\right) \log p\left(a_i a_j\right) \] 条件熵: \[ H\left(X_2 \mid X_1\right)=-\sum_{i=1}^q \sum_{j=1}^q p\left(a_i a_j\right) \log p\left(a_j \mid a_i\right) \] 因为 \[ p(a_ia_j)=p(a_j|a_i)p(a_i) \] 所以 $$ \[\begin{aligned} H(X_1,X_2)& =-\sum_{i=1}^q\left[\sum_{j=1}^q p\left(a_i a_j\right) \right] \log p\left(a_i\right)-\sum_{i=1}^q\sum_{j=1}^q p\left(a_i, a_j\right) \log p\left(a_j \mid a_j\right) \\ & =-\sum_{i=1}^q p\left(a_i\right) \log p\left(a_i\right)-H(X_1|X_2)\\ & =H(X_1)-H(X_1|X_2)\\ \end{aligned}\]$$ 即:联合熵=前一个符号的信息熵+前一个符号已知时信源发出下一个符号的条件熵。
对于平稳有记忆N次扩展信源,有平均符号熵: \[ H_N(X) \stackrel{\text { def }}{=} \frac{1}{N} H\left(X^N\right)=\frac{1}{N} H\left(X_1, X_2, \cdots X_N\right) \] 当信源符号序列长度趋于无穷时,有极限熵: \[ H_{\infty}(X) \stackrel{\text { def }}{=} \lim _{N \rightarrow \infty} H_N(X)=\lim _{N \rightarrow \infty} \frac{1}{N} H\left(X^N\right) \] N次扩展信源熵的性质有:
- 条件熵\(H\left(X_N \mid X_1 X_2 \cdots X_{N-1}\right)\)随\(N\)增加非递增
- 平均符号熵\(H_N(X)\)随\(N\)增加非递增
- 极限熵存在,且\(H_\infty(X)=\lim _{N \rightarrow \infty} H\left(X_N \mid X_1 X_2 \cdots X_{N-1}\right)\)
- \(H_N(X) \geq H\left(X_N \mid X_1 X_2 \cdots X_{N-1}\right)\)
马尔可夫信源
如果系统在时刻\(n-1\)处于状态\(S_{i_{n-1}}\),那么将来时刻\(n\)的状态\(S_n\)和过去的\(1,2,3,\cdots,n-2\)都无关,只和现在时刻\(n-1\)的状态有关,这样的特性叫做马尔可夫特性,这样的系统叫做马尔可夫链(有限状态一阶马尔可夫链),用数学语言描述,就是: \[ \begin{aligned} & P\left(X_n=S_{i_n} \mid X_{n-1}=S_{i_{n-1}}, X_{n-2}=S_{i_{n-2}}, \cdots, X_1=S_{i_1}\right) \\ = & P\left(X_n=S_{i_n} \mid X_{n-1}=S_{i_{n-1}}\right) \end{aligned} \] 引入转移概率: \[ P_{ij}(m,n) \] 意思是已知时刻\(m\)系统处于状态\(S_i\),经过\(n-m\)步后系统转移到状态\(S_j\)的概率。在有限状态一阶马尔可夫链中,我们主要关注\(P_{ij}(m,m+1)\),简记为\(P_{ij}(m)\),即: \[ p_{i j}(m)=P\left(X_{m+1}=S_j \mid X_m=S_i\right) \] 类似地,定义\(k\)步转移概率为\(P_{ij}^{(k)}(m)=P_{ij}(m,m+k)\)。
因为系统在任意时刻都可能处于任意状态,所以一般用状态转移矩阵来描述,\(m\)时刻的\(k\)步转移矩阵定义为: \[ \mathbf P^{(k)}(m)=\{p_{ij}^{(k)}(m),i,j\in S\} \] 如果在马尔科夫链中,\(p_{ij}(m)=p_{ij}\),即转移概率和\(m\)无关,那么称之为齐次马尔可夫链,也叫遍历的马尔可夫链。齐次马尔科夫链的转移矩阵可以表示为: \[ \mathbf{P}=\left[\begin{array}{cccc} p_{11} & p_{12} & \cdots & p_{1 j} \\ p_{21} & p_{22} & \cdots & p_{2 j} \\ \vdots & \vdots & & \vdots \\ p_{j 1} & p_{j 2} & \cdots & p_{jj} \end{array}\right] \] 且有C-K方程: \[ \mathbf{P}^{(n+m)}=\mathbf{P}^{(n)} \cdot \mathbf{P}^{(m)} \] 若齐次马尔可夫链对一切\(i,j\)存在不依赖于\(i\)的极限: \[ \lim _{n \rightarrow \infty} p_{i j}^{(n)}=p_j \] 且满足:
\[ p_j\geq 0 \]
\[ p_j=\sum_{i=1}^\infty p_ip_{ij} \]
\[ \sum_j p_j=1 \]
那么称其有平稳性,\(p_j\)称为平稳分布,其中\(p_i\)是马尔科夫链的初始分布。意思是,无论系统从哪个状态出发,当转移的步数足够多时,转移到特定状态的概率都近似等于一个常数。稳态分布存在的充要条件是:存在一个正整数\(N\),使得\(P^N\)中的所有元素都大于零。
如果稳态分布存在,那么可以设稳态分布矢量\(\mathbf W=[w_1,w_2,\cdots,w_n]\),其中\(w_j\)表示稳态分布中的\(p_j\),通过解方程 \[ \mathbf{W=WP} \] 可以求解稳态分布,且稳态分布具有唯一性。
具有\(m\)阶马尔可夫特性(即下一个时刻输出的符号仅和前\(m\)个符号有关,和更前的符号无关)的信源称为\(m\)阶马尔可夫信源。遍历的\(m\)阶马尔可夫信源的极限熵为其\(m\)阶条件熵,即: \[ H_\infty=H_{m+1}=H\left(X_{m+1} \mid X_1 X_2 \cdots X_m\right) \]
相关性和冗余度
信源输出符号间的依赖关系越强,信源熵就会减小。这就是信源的相关性。当信源输出符号间的相关程度越长,信源的实际熵越小,趋于极限熵;当信源输出符号之间不存在相互依存关系且为等概分布,信源实际熵趋于最大熵\(H_0=\log q\),其中\(q\)是信源输出符号集的符号数目。定义信源剩余度: \[ R=1-\frac{H_{\infty}}{H_0} \]
本站的运行成本约为每个月5元人民币,如果您觉得本站有用,欢迎打赏:
