使用Matlab训练卷积神经网络完成表情包分类任务
在本项目中,我使用Matlab 2019a软件搭建了两个模型,分别是自己设计的卷积神经网络模型,和参考了VGG结构的卷积神经网络模型,在数据量为4697的emoji表情包数据集上进行测试,完成表情包图像分类任务,最终分类准确率为93.8%。成绩不算高,只能说可以解决有无问题。
Matlab 语言要求所有函数都定义在代码的最后,但是为了阅读顺畅,本文档修改了部分代码的顺序。如果需要运行代码,请下载源代码文件。因版权原因,无法提供数据集和测试集。
[toc]
概述
在本项目中,我使用Matlab 2019a软件搭建了两个模型,分别是自己设计的卷积神经网络模型,和参考了VGG结构的卷积神经网络模型,在数据量为4697的emoji表情包数据集上进行测试,完成表情包图像分类任务,最终分类准确率为93.8%。
其中,自己设计的卷积神经网络共有6个卷积层和2个全连接层,参考VGG结构的卷积神经网络有6个部分,其中前五个部分为2~3个卷积层的级联,第6个部分为三个全连接层。
在训练时,将数据集中的90%用作训练集,10%用作测试集,并在训练集上使用augmentedImageDatastore方法进行数据增强。考虑到数据集的特性,采取了随机水平翻转、随机缩放、随机水平/竖直位移四种方法进行增强。
用训练集训练,调整超参数,当模型的表现达到较好的水平时,再将整个数据集当作训练集,训练出最终的模型。
用上面的训练过程,调整不同的训练设置(例如将图像进行灰度/彩色处理),训练出多个不同的神经网络。在最终生成测试表格时,用这七个网络进行投票选择,按每个网络预测的前两名标签的置信概率加权投票,选出最终的预测标签。
网络设定
卷积神经网络
卷积神经网络(CNN)是一种深度学习模型,它在图像识别、视频分析、自然语言处理等领域表现出色。CNN的原理基于生物学中的视觉皮层机制,特别是动物视觉系统对空间层次结构的处理方式。卷积神经网络的原理基于以下几点:
局部感受野:
卷积神经网络中的每个神经元都只对输入数据的一个局部区域(即感受野)进行响应,这与生物视觉系统中的局部感受器类似。相同的权重模式可以在视觉皮层的不同位置复制,以检测不同位置的相同特征,这种局部连接方式大大减少了网络的参数数量。
权值共享
在卷积层中,同一个卷积核(或滤波器)的权重在整个输入数据上是共享的。这意味着无论输入图像有多大,使用的卷积核大小是固定的,这有助于检测图像中的局部特征,并且减少了模型的参数量。
池化
也叫做下采样或汇聚层,对不同空间位置的特征值进行聚合统计。常用池化操作有最大池化(Max Pooling)、平均池化(Mean Pooling)、随机池化(Stochastic Pooling)往往在卷积层后面,实现降维,减少参数和计算量,防止过拟合,使模型对尺度、平移、旋转变化具有一定的不变性。
多层处理
CNN通常包含多个卷积层和池化层,每一层都在提取不同层次的特征。较低层次可能捕捉简单的特征(如边缘),而较高层次则可能捕捉更复杂的特征(如物体的部分)。
在我自己设计的CNN中,参考课程PPT,共有1个卷积块,其中有6个卷积层,卷积核大小为3x3,通道数分别为16、32、64、128、256、512,卷积层之间有ReLU激活层;有两个全连接层,规模分别为1000和50,全连接层之间有dropout。
相关代码如下:
1 | |
VGG网络
VGG(Visual Geometry Group)网络是由牛津大学的视觉几何组在2014年提出的深度学习模型,它在当年的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛中取得了分类任务的亚军。VGG网络以其简洁性和卓越的性能而受到广泛关注,并且至今仍被广泛应用于图像识别、目标检测等计算机视觉任务中。在本项目中,我试图自己构造了VGG16.
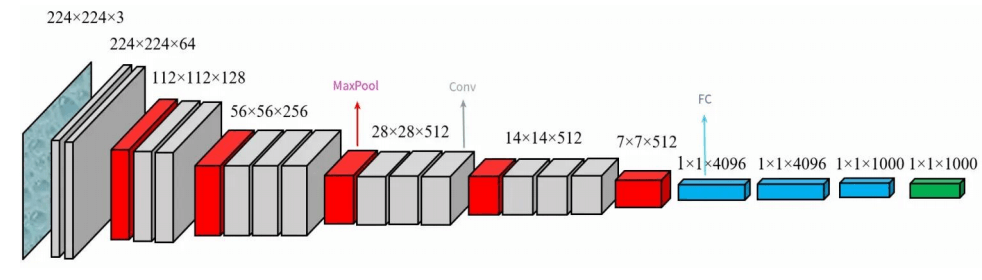
VGG16包含了5个卷积块,每个卷积块分别包含2、2、3、3、3个卷积层,每个卷积层的通道数依次是64、128、256、512、512;包含了3个全连接层,规模分别为4096、4096和50。全连接层之间有dropout。
相关代码如下:
1 | |
数据预处理
在数据预处理阶段,我主要使用augmentedImageDatastore方法进行数据增强。
图像分类中的数据增强是一种提高模型泛化能力和性能的技术,特别是在标注数据有限的情况下。数据增强通过创建图像数据的变体来模拟训练集中的多样性,帮助模型学习到更加鲁棒的特征。数据增强的主要方法有随机旋转、随机缩放、随机裁剪、随机翻转、颜色变换、仿射变换、添加噪声等。考虑到图标数据集比较风格化,也没有太多的旋转、倒置等情况,我采取了随机水平翻转、随机缩放、随机水平/竖直位移四种方法进行增强。
在读取阶段,我将所有图像放缩到同一大小,并对图像的数据进行归一化处理。
相关代码如下:
1 | |
训练过程
经过多次尝试,选择以下训练选项:
1 | |
用trainNetwork命令进行训练:
1 | |
在两个模型上的训练曲线如下:
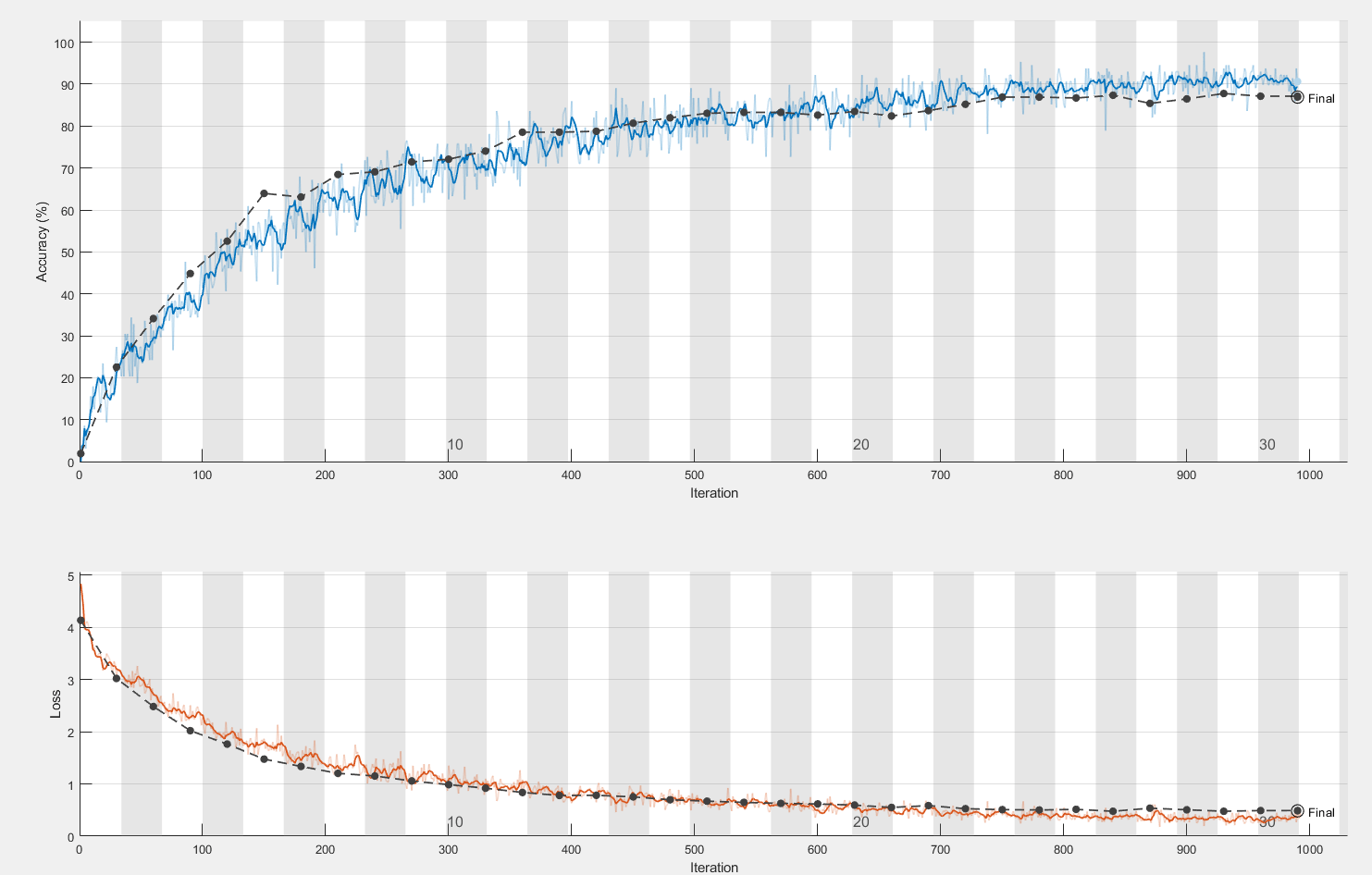
上图是在自定义CNN上训练的图像,因连续5次测试,测试结果未见明显改善而终止。
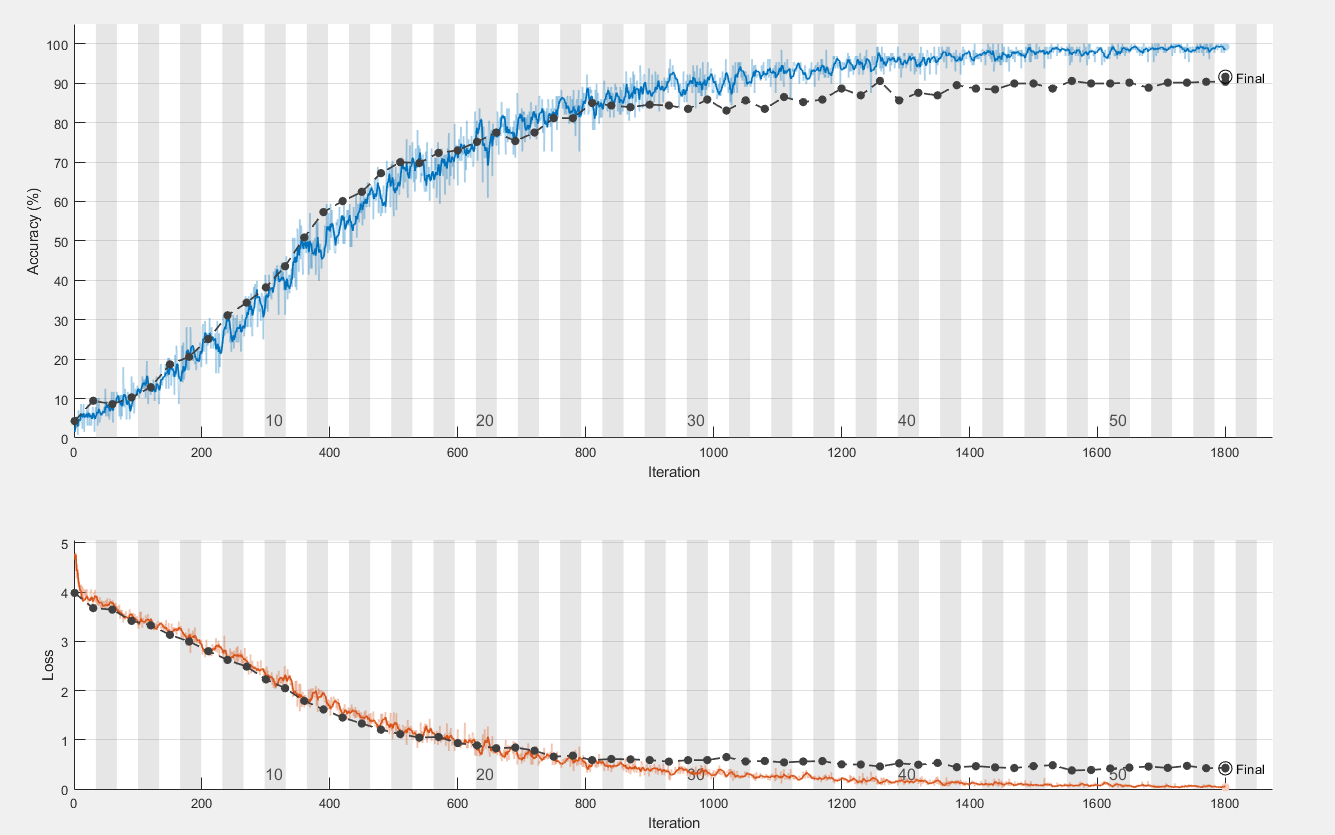
观察曲线,可以发现在自定义CNN网络上拟合比较适中,最终是准确率是86.9%;在仿VGG网络上出现了轻度的过拟合现象,最终的准确率是91.6%,为了修正过拟合,采取过增大正则化系数,增强数据随机性等多种操作,但是最后仍然有轻度的过拟合现象。
后续处理
为了进一步增加分类准确率,观察了一下模型在测试集上的混淆矩阵:


发现同一个模型结构,修改部分参数训练出的模型,它们所犯的错误是不太一样的。据此,可以采取集成学习方法:通过调整数据增强方法、调整图像大小、调整图像通道数(灰度/彩色)、调整训练超参数、在图像上加不同的噪声,最终通过上面的两个架构训练出11个模型。在最终生成测试表格时,用这11个网络进行投票选择,按每个网络预测的前两名标签的置信概率加权投票,选出最终的预测标签。
相关代码如下:
1 | |
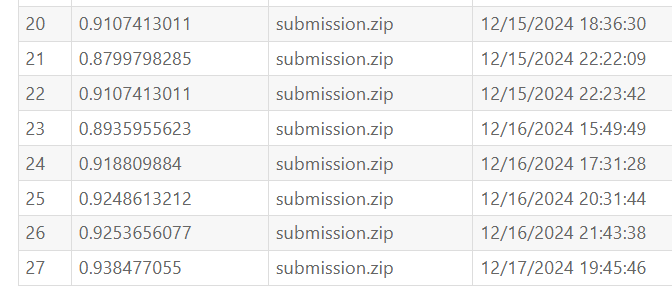
经过实际检验,投票方法确实可以提升准确率。其中编号为20-24的提交都是单个模型预测的结果,编号25、26的提交是7个模型投票的结果,编号27是11个模型投票的结果。
本站的运行成本约为每个月5元人民币,如果您觉得本站有用,欢迎打赏:
